Simple Try for the Instagram Engineering Challenge
2011年11月13日 02:25
Introduction
在@Teaonly的微博中看到这个转帖:
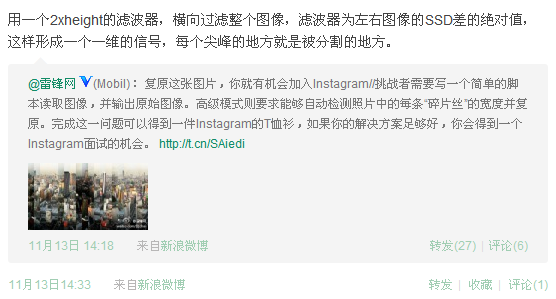
Instagram公司给了一张把图像切片、打乱、组合成的图像。[1]
原图是:

要的是自动对乱序的图像切片进行重新排列,组成原始图片:

雷锋网有介绍。[2]
Instagram给出了图像尺寸,356×640,切片的宽度是32。对于如何自动找width的问题,Teaonly提出了方案。这里简单用32。
图片质量很好,只是简单的切割,没有任何degradation操作,于是使用了一个工程性的方法搞定:
Motivation
在切片相接处,两侧像素值差异很小,依次来判别是否相接。
Method
根据差异值进行统计,排序,就可以得到一个切片的左边可能是谁,右边可能是谁的hypothesis;排序的时候,取最相近的前两名。对左侧的判定结果,使用右侧排序结果进行hypothesis vertification。最后,可以得出最右侧元素,依次向前track出所有的图像切片,拼接即得原始图。
两列像素值差异计算公式简单用:

在计算的时候,我只用了灰度信息,即把原图转化为灰度图,这样计算简便。也可以计算color的3维欧氏距离。不过,对这张图片grayscale就足够应付了。
Implementation
% The Image Unshredder script
%
% write by visionfans @ 2011.11.14
clear;clc;close all
% load image
imgOri = imread('http://instagram-static.s3.amazonaws.com/images/TokyoPanoramaShredded.png');
% get image size
nClip = 20;
[nrows ncols nCh] = size(imgOri);
widClip = ncols / nClip;
xAxis = linspace(0, ncols, nClip+1) + 1;
% show every clip, format
lSide = zeros(nrows, nClip);
rSide = zeros(nrows, nClip);
imgColClip = uint8(zeros([nrows widClip nCh nClip]));
imgGray = rgb2gray(imgOri);
figure;
for i = 1:nClip
% crop image patch
rectArea = [xAxis(i) 1 31 nrows];
imgClip = imcrop(imgGray, rectArea);
imgColClip(:,:,:,i) = imcrop(imgOri, rectArea); % for show
subplot(2, nClip/2, i); imshow(imgColClip(:,:,:,i));title(num2str(i));
% statics side line
lSide(:, i) = imgClip(1:end, 1);
rSide(:, i) = imgClip(1:end, end);
end
% calculate coloum pixel diversity
distMat = zeros(nClip, nClip);
for i = 1:nClip
for j = 1:nClip
if i==j
distMat(i, j) = Inf;
else
distMat(i, j) = sum(abs(lSide(:, i) - rSide(:,j)));
end
end
end
% find candidate matchings
[~, lMatch] = sort(distMat');
[~, rMatch] = sort(distMat);
candsAll = zeros(2, nClip);
for i = 1:nClip
lcands = lMatch(1:2,i);
for j = 1:2
rcands = rMatch(1:2, lcands(j));
if ismember(i, rcands)
candsAll(j,i) = lcands(j);
end
end
end
% filter repetition
rightElement = setdiff(1:nClip, unique(candsAll(1,:)));
if numel(rightElement)~=1, error('Need more elaborate check.'); end
% get result
imgOrder = zeros(1,nClip);
idxNext = rightElement;
for i = 1:nClip
imgOrder(i) = idxNext;
idxNext = candsAll(1, idxNext);
end
imgOrder = fliplr(imgOrder);
outImg = [];
for i = 1:nClip
outImg = [outImg imgColClip(:,:,:,imgOrder(i))];
end
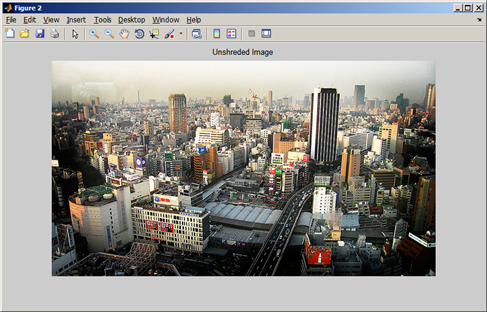
figure;imshow(outImg);title('Unshreded Image');
Result
Segmentation of image strips,每条宽32个pixels:

Sort result:
imgOrder = [ 9 11 15 17 19 14 8 4 3 12 5 20 18 13 7 16 2 6 1 10 ]
Unshreded Image:
Discuss
更多需要考虑的情况:
1. 如何自动检测切片的分割位置,其实,这里给了基本假设是直线切割,如果不是直线怎么办。
2. 对于低质图像,本文中简单的边界差异比较算法就无效了,要考虑切片内部内容。'
3. 对于非直线切割的情况,如何利用边界特征去进行匹配。
3. 当前算法,难以处理通用的拼接。更多问题,有兴趣的同学可以继续挖下去。
Just for fun! ^-^
References
[1] Instagram Engineering Challenge: The Unshredder,http://instagram-engineering.tumblr.com/
[2] 复原这张图片,你就有机会加入Instagram, http://www.leiphone.com/join-instagram.html?jtss=tsina